1.5 硬件栈
如果我们现在在讨论数据结构,那么栈就是一种数据结构,一个支持两种操作的容器,新元素可以被放在栈的顶部(push);而栈顶的元素也可以被拿走(pop)。
这种数据结构在硬件层面可以支持。并不是说我们需要独立的栈内存来实现它。实际上只是使用了两条机器指令(push 和 pop)和一个寄存器(rsp)就实现了这种支持。rsp 寄存器保存了栈顶的元素位置。而两条操作指令具体的行为类似这样:
push 元素
按照元素大小(2,4 和 8 字节都是允许的),rsp 的值会减 2,4 或者 8。
新元素会被存储在从 rsp 刚刚取走的起始地址位置。
pop 元素
栈顶的元素被拷贝到寄存器/内存。
rsp 的值按元素的大小增加。图 1-7 展示了一个增强了的架构。
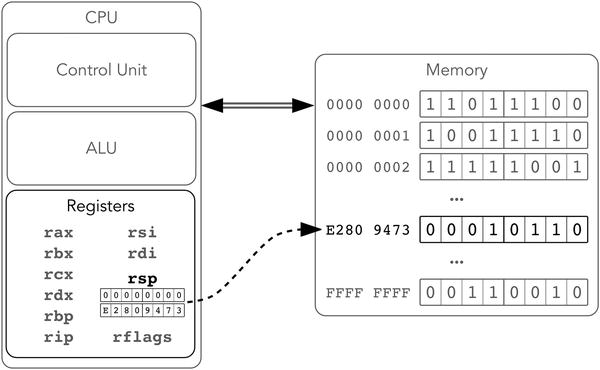
图 1-7.Intel 64, 寄存器和栈
硬件栈可以帮助高级语言来实现函数调用。当函数 A 调用另一个函数 B 时,其使用栈保存当前函数的计算上下文,当 B 被销毁之后再返回到该上下文中。
下面是一些硬件栈的重要特性,都附带了说明:
- 没有栈为空的场景,即使我们没有进行过 push 操作。pop 命令一样可以被执行,只是可能会返回一条垃圾信息。
- 栈向零地址方向扩展。
几乎所有的操作数都可以认为是带符号整数,因此可以使用带符号的 bit 对其进行扩展。例如执行一条 push,将 B916 推进栈,会让栈存储下面这样的信息单元:
0xff b9, 0xffffffb9 or 0xff ff ff ff ff ff ff b9
push 默认操作 8 字节操作数。因此 push -1 会在栈上保存 0xff ff ff ff ff ff ff ff。大多数支持栈的架构都会用某个寄存器来进行类似的操作。不过不同的架构区别在于其使用的相对地址的含义。在某些架构上地址表示下一个元素的起始地址,下一次执行 push 时即使用到该地址。在另一些架构上则是存储最后一个已经被推进了栈的元素的起始地址。
■Working with Intel docs: 如何阅读指令描述。打开文档第二卷[15]。找到 push 指令的页。描述以一张表格开始,为了达到我们的目的,我们只需要检查 OPCODE,INSTRUCTION,64-BIT MODE 和 DESCRIPTION 这几列。OPCODE(operation code) 字段定义了编码后的机器指令。可以看到有选项存在,每个选项对应不同的 DESCRIPTION。这表示有时候机器指令并不只是操作数的变化,可能具体的 OPCODE 也会变。
INSTRUCTION 表示的是指令的助记符,以及操作数的类型。这里的 R 表示通用任意的通用寄存器, M 表示内存位置,IMM 表示了立即值(e.g.整数常量,例如 42,1337)。还有一个数值定义了操作数的长度,如果只能使用特定的寄存器的话,会直接给出名字。例如:
- push r/m16---将一个 16 位的寄存器或者从内存里取的 16 位数推进栈。
- push CS---把段寄存器 cs 推进栈。
DESCRIPTION 这一列对指令的效果做了简单的解释。不过对于简单的理解和使用指令已经足够了。
- 阅读 push 的更详尽的说明。什么时候操作数不会进行符号位扩展?
- 解释 push rsp 时,会对内存和寄存器产生的全部影响。